K8S 应用故障调试
2022-03-26
K8S 应用页面随机性失败问题
该问题排查过程中使用了 K8S 应用故障排查一般思路和方法,包括:
- 如何快速定位应用有问题还是网络不能访问
- 如何将应用收缩到单副本,避免负载均衡干扰
- 如何指定将应用部署在指定节点上,排除跨节点干扰
- 如何通过 NodePort 对外暴露 Service
- 如何排查 K8S 上应用的 pod 日志
- 如何找到 Pod 的虚拟网卡,对虚拟化上的通信数据抓包
- 如何检查 Pod 之间的通联性(ICMP 和 DNS 解析)
- 如何通过 wireshark 分析数据包
- 如何界定 Overlay 网络存在问题还是底层云平台网络存在问题?
- 如何定位 MTU 问题?
因此详细记录了本次排查的思考和操作过程,为后续排查 K8S 应用故障问题提供借鉴。
1. 问题背景
公司的产品是一个 K8SaaS 平台,提供类似公有云的 EKS 服务。
测试人员报告:
- K8SaaS 平台的底层云平台是 OpenStack(Train 版本),通过 K8SaaS 新建的 K8S 集群的 Node 节点就是 OpenStack 上的 VM。
- 在 K8SaaS 第一次创建的 3 Master 节点上,业务应用运行正常。但再次创建一个 3 Master 节点的 K8S 集群,同样的业务应用却无法正常访问。
- 该业务应用通过 Nodeport 暴露出来,浏览器通过 OpenStack floating IP 加端口访问此应用,根路由
/没有响应。
拓扑图:
┌───────────────────────┬─────────────────────────┐
│ K8S-1-APP-OK │ K8S-2-APP-NOK │
├───────┬───────┬───────┼───────┬────────┬────────┤
│ VM-1 │ VM-2 │ VM-3 │ VM-4 │ VM-5 │ VM-6 │
├───────┴───────┴───────┴───────┴────────┴────────┤
│ OpenStack Train │
└─────────────────────────────────────────────────┘
2. 初步分析
测试同事反馈的 K8SaaS 产品发版已久,相对稳定,对接该问题中的业务应用没有出现过类似问题,因此猜想是配置异常所致。
3. 排查过程
3.1 厘清相关组件和调用逻辑
首先是理清该问题相关的业务应用组件。访问应用业务页面时,相关的两个组件分别是:apiserver 和 console
[root@vm-4 ~]# kubectl get po -n app-system
app-system apiserver-6848c8c686-z2p6h 1/1 Running 0 9h
app-system console-67df74d8df-hsqmh 1/1 Running 0 26h
问题发生时,前端调用的逻辑关系是:
[Browser] -> [fip 172.16.150.43] -> [vm-4 10.1.0.11 nodeport 32000] -> [console svc 10.96.36.119:80] -> [console(多副本)] -> [apiserver svc 10.96.98.148:80] -> [apiserver(多副本)] -> [etcd]
考虑到发生问题的 k8s 集群搭建在 OpenStack 云上,磁盘底层是多副本 Ceph,网络是 Calico over OVS vxlan,因为磁盘自身的性能问题,或者网络卡自身的物理问题(千兆网卡自动降速为十兆),曾经导致过一些 ETCD leader change 的随机问题。但这类问题一般现象是会导致业务应用安装失败,而不是安装之后无法访问,与我们现在看到的现象不吻合。
所以接下来按常规思路逐步定位排查。
3.2 进一步确认问题现象
在问题刚爆出来的时候,现象是不明确的。对于此问题,测试人员的第一描述是通过 FIP(K8S 的 Node 节点是 OpenStack 上的 VM)无法访问应用业务页面。此时我们做简单的故障重现和干扰排除:
3.2.1 客户端访问
从客户端浏览器能不能访问:http://<fip>:32000,发现确实不能访问,看 F12,发现请求没有返回。
3.2.2 登录到 vm-4 节点上检查
检查对应端口是否开放?可以看到服务正常,端口开放。
[root@vm-4 ~]# netstat -putln | grep 32000
tcp 0 0 0.0.0.0:32000 0.0.0.0:* LISTEN 12550/kube-proxy
在 Node 节点上直接访问 32000 NodePort 端口。这里有一个比较蹊跷的地方,访问 localhost 的 32000 确实是不通的,原因没有深究,后续可以看下本地回环为什么不通。
[root@vm-4 ~]# curl http://localhost:32000
^C
[root@vm-4 ~]# curl http://127.0.0.1:32000
^C
然后检查对应 service 的 80 端口,或者 pod 对应的端口。
先检查 service 的端口
[root@vm-4 ~]# kubectl get svc -A | grep console
app-system console NodePort 10.96.36.119 <none> 80:32000/TCP 33h
确认 service 能正常访问
[root@vm-4 ~]# curl http://10.96.36.119
Redirecting to <a href="/login">/login</a>.
注意:如果 servce 不能正常访问,还可以进一步检查 pod 是否正常,是否能正常访问 pod 里的服务。
鉴于服务正常,NodePort 端口正常,主机访问不到是不合理的,再尝试用主机 IP 访问
[root@vm-4 ~]# ip a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc pfifo_fast state UP group default qlen 1000
...
inet 10.1.0.11/24 brd 10.1.0.255 scope global dynamic eth0
[root@vm-4 ~]# curl http://10.1.0.11:32000
Redirecting to <a href="/login">/login</a>.
至此,确认 console 本身应该能被访问到,localhost 和 127.0.0.1 访问失败应该是 iptables 规则设置或者其他问题,不应该影响外部访问。
此时,可以确认 vm-4 上的 console 服务,根路由访问没有问题,如果客户端还是不能访问,那可能是 OpenStack FIP 网络映射有问题。我们还是回到主机端检查。
3.2.3 回到主机端
用 curl 命令继续检查,发现 curl 能工作
$ curl http://172.16.150.43:32000
Redirecting to <a href="/login">/login</a>.
此时可以知道,在浏览器上访问 http://172.16.150.43:32000 可能是浏览器自身存在缓存,或者其他问题导致浏览器未真实发送,或者未加载返回。Chrome 浏览器在出现升级提示后,访问部分网页,有时会显示空白页面,升级后能恢复。还有一些问题和缓存有关,清理缓存能恢复。无论如何,curl 能正常返回,说明客户端访问 FIP 32000端口没有问题。
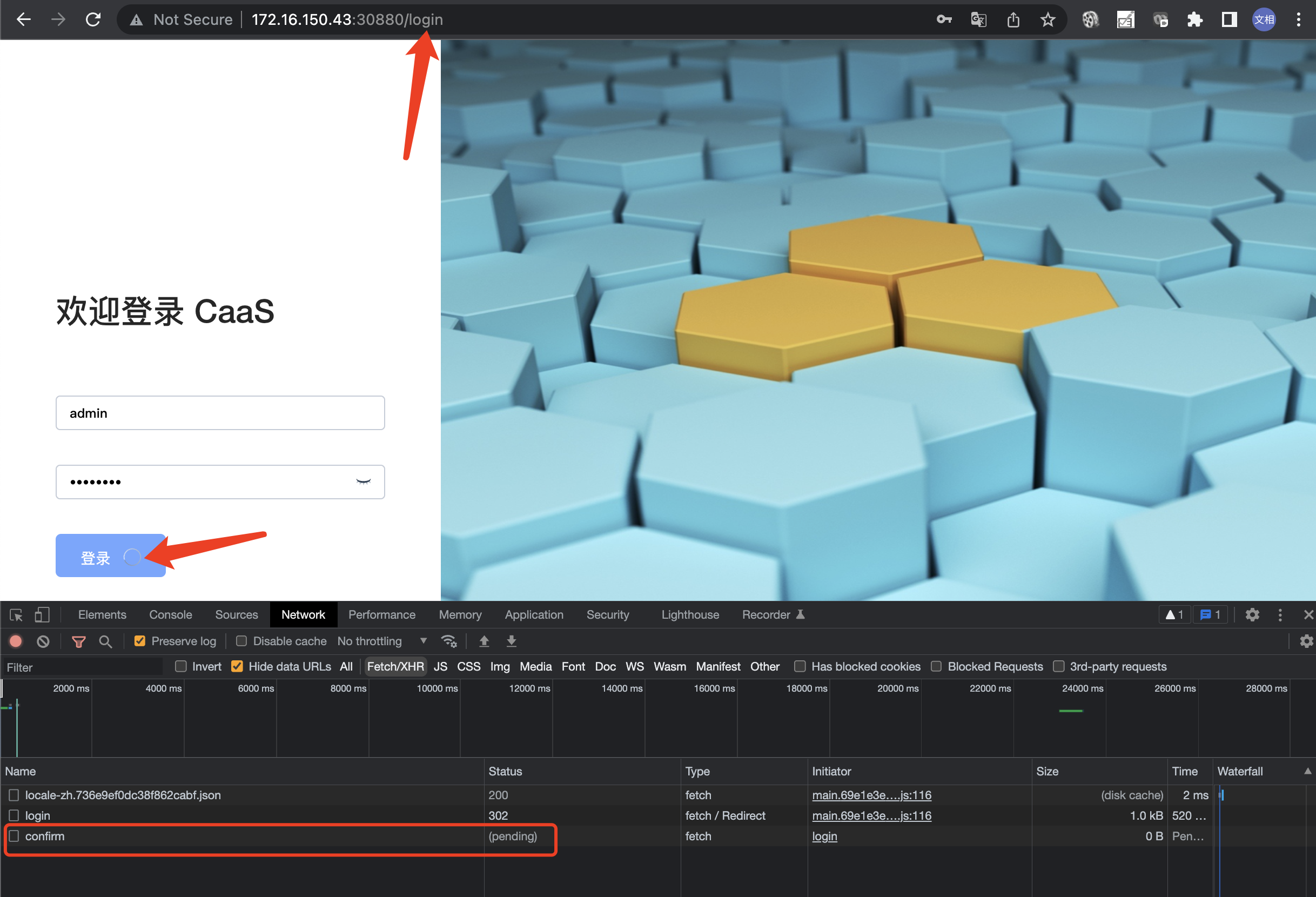
此时另一位测试同学说她能访问登录页面,需要在根路由加上 /login,验证,果然可以跳转到登录页面,但登录时一直显示转圈,无法登录。
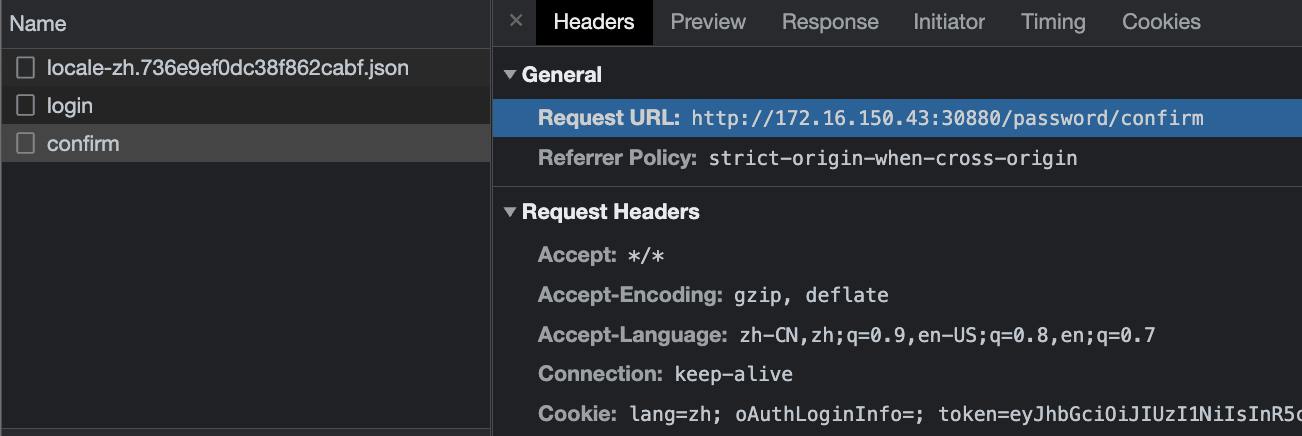
F12 检查,是 http://172.16.150.43:32000/password/confirm 请求未能正常返回:
多尝试几次,发现问题现象随机且多变:
- 时而能登录,但部分页面无法响应,时而又不能登录。
- 登录后时而跳转到重新设置密码的页面(第一次登录需要),时而直接进入业务页面(非第一次登录,重置过密码后就会直接跳入业务页面)
- 部分页面不能偶发性正常工作,不断刷新就可以随机重现
至此,我们进一步明确了问题现象,继续排查。
3.3 排除多副本干扰
console 和 apiserver 都是 3 副本 deployment,通过 k8s service 对外暴露 Cluster IP(其中 console 暴露
NodePort),鉴于问题的随机特征,大概率是多副本服务中某些副本对接有问题。我们先对副本数进行收缩,排除干扰。
kubectl scale deploy apiserver -n app-system --replicas=1
kubectl scale deploy console -n app-system --replicas=1
确定 pod 都收缩到单副本后,浏览器检查,现在可以稳定重现登录失败,不再随机。
注意:如果这里简单收缩之后问题消失,可以尝试只放开
apiserver3 副本,保持console单副本;或者只放开console3 副本,保持apiserver单副本。多测几次,逐步定位是哪个服务在多副本时有问题。
至此,我们能稳定重现问题:客户端 GET /password/confirm 没有返回。
3.4 检查此问题是否与跨节点通信有关
接下来我们检查此问题是否与跨节点通信有关。
首先检查两个 pod 是否位于不同节点,可以看到两个 pod 分别位于 vm-4 和 vm-5。
[root@vm-4 ~]# kubectl get po -n app-system -o wide
...
apiserver-6848c8c686-z2p6h 1/1 Running 0 13h 172.25.235.30 vm-5 <none> <none>
console-67df74d8df-hsqmh 1/1 Running 0 29h 172.25.127.32 vm-4 <none> <none>
然后将两个 pod 调度到同一节点(将 apiserver 调度到 vm-5)
kubectl edit deploy apiserver -n app-system
参考:https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#nodename 为 apiserver 的 pod template 添加 nodeName,使其调度到 vm-4
[root@vm-4 ~]# kubectl get deploy apiserver -n app-system -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
...
name: apiserver
namespace: app-system
spec:
...
replicas: 1
template:
metadata:
...
spec:
nodeName: vm-4
...
问题不再重现,页面可以登录,可以正常访问。再将 apiserver 调度到 vm5,问题稳定重现,无法登录。再调度到同一节点,页面可以正常登录。
至此,确认问题与跨节点有关。可能是节点间 pod 通信异常。
3.5 排查跨节点问题
恢复将 apiserver 调度到 vm5,令问题稳定重现。
3.5.1 检查两个 pod 是否能 ping 通
进入 pod 直接 ping,发现 pod 中有 ping 命令,但是需要 root 权限。
如果 pod 中没有 ping 命令,我们需要进入容器的 netns 去 ping,后面会讲
[root@vm-4 ~]# kubectl exec -it console-67df74d8df-hsqmh -n app-system -- /bin/sh
/opt/app/console $ ping 172.25.127.36
PING 172.25.127.36 (172.25.127.36): 56 data bytes
ping: permission denied (are you root?)
该系统中的容器运行时是 docker,我们可以用 root 权限进 docker 容器去 ping,先找到对应的 docker 容器
[root@vm-4 ~]# docker ps | grep console
bdc1b0ca20b0 eed47a820184 "docker-entrypoint.s…" 30 hours ago Up 30 hours k8s_console_console-67df74d8df-hsqmh_app-system_7c8f9f44-7dc4-4fb4-9205-1b4aa96ec1c4_0
5ec54a2e88da 192.168.200.101:5000/pause:3.2 "/pause" 30 hours ago Up 30 hours k8s_POD_console-67df74d8df-hsqmh_app-system_7c8f9f44-7dc4-4fb4-9205-1b4aa96ec1c4_0
第一个 docker 容器是业务容器,第二个 POD 容器,两者共享 netns。POD 容器提供的工具比较少,因此一般进业务容器操作。
[root@vm-4 ~]# docker exec -it -uroot bdc1b0ca20b0 /bin/sh
/opt/app/console # ping 172.25.127.36
PING 172.25.127.36 (172.25.127.36): 56 data bytes
64 bytes from 172.25.127.36: seq=0 ttl=63 time=0.502 ms
64 bytes from 172.25.127.36: seq=1 ttl=63 time=0.313 ms
64 bytes from 172.25.127.36: seq=2 ttl=63 time=0.365 ms
64 bytes from 172.25.127.36: seq=3 ttl=63 time=0.416 ms
64 bytes from 172.25.127.36: seq=4 ttl=63 time=0.421 ms
...
^C
--- 172.25.127.36 ping statistics ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 0.239/0.375/0.572 ms
确定能 ping 通,并且是一直通,没有偶发性不通。说明不是常见的 ipip 协议在 OpenStack VM 上通信失败问题(OpenStack 上安全组没有放行 IPIP 协议,或者 DPDK 启用不支持 IPIP 协议)
3.5.2 检查 console 是否能解析 apiserver 服务
考虑到 console 访问 apiserver 是通过 svc 访问,而不是直接访问 pod ip,所以需要尝试解析 apiserver,看是否有解析问题。
/opt/app/console # nslookup apiserver
Server: 10.96.0.10
Address: 10.96.0.10:53
Name: apiserver.app-system.svc.cluster.local
Address: 10.96.98.148
可以看到能正常解析。
注意:如果业务容器中没有 nslookup 命令,可以参考:https://gitee.com/dev-99cloud/training-kubernetes/blob/master/doc/class-01-Kubernetes-Administration.md#37-deamonset--statefulset,在
app-system里启动 busybox pod,进行 nslookup 检查。后面有介绍。
3.5.3 检查 console 是否能正常访问 apiserver
检查 apiserver 的服务端口,起在 80 端口
[root@vm-4 ~]# kubectl get svc -A | grep api
app-system apiserver NodePort 10.96.98.148 <none> 80:31000 TCP 35h
然后从 console 的容器中访问此端口,业务容器中没有 curl 命令
[root@vm-4 ~]# docker exec -it -uroot bdc1b0ca20b0 /bin/sh
/opt/app/console # curl
/bin/sh: curl: not found
/opt/app/console # exit
可以参考:https://gitee.com/dev-99cloud/training-kubernetes/blob/master/doc/class-01-Kubernetes-Administration.md#37-deamonset--statefulset,在 app-system 里启动 busybox pod
[root@vm-4 ~]# kubectl run curl --image=radial/busyboxplus:curl -n app-system -i --tty
[ root@curl:/ ]$ curl http://apiserver
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot GET path \"/\"",
"reason": "Forbidden",
"details": {
},
"code": 403
}
可以看到 console 可以正常访问 apiserver。
至此,确认 pod 连通性没有问题,console 可以正常访问 apiserver。这不是一个常见的跨节点连通性问题,因此需要从业务的应用逻辑入手逐步排查。
3.6 排查日志
对于应用异常,可以先看一下应用日志:
[root@vm-4 ~]# kubectl logs -f console-67df74d8df-hsqmh -n app-system
<-- GET /login 2022/03/26T22:56:37.980
--> GET /login 200 44ms 15.16kb 2022/03/26T22:56:38.023
<-- POST /login 2022/03/26T22:56:40.583
--> POST /login 302 405ms 65b 2022/03/26T22:56:40.987
<-- GET /password/confirm 2022/03/26T22:56:41.015
^C
没有更多日志,就卡在这里。更早之前有一些报错,但不是在本次重现中发生的,未必有关。
再检查 apiserver 日志,没有日志产生,前序看到一些 token expired 的告警,但是是之前的,未必有关联,仅做记录。
[root@vm-4 ~]# kubectl logs -f apiserver-6848c8c686-z2p6h -n app-system
...
W0326 22:18:34.150068 1 jwt_token.go:52] token is expired by 9h20m46s
^C
两个 pod 的日志中都没有看到明显报错。
接下来,进一步兵分两路进行排查:
- 检查应用业务代码,看
GET /password/confirm在console中的处理逻辑,以及向apiserver发了什么请求? - 继续尝试网络抓包,看网络包中能发现什么问题。
3.7 应用代码的排查
首先暴露 apiserver 服务,放开 nodeport,这需要编辑 svc,参考:https://kubernetes.io/zh/docs/concepts/services-networking/service/#type-nodeport
[root@vm-4 ~]# kubectl get svc apiserver -n app-system -o yaml
apiVersion: v1
kind: Service
metadata:
...
name: apiserver
namespace: app-system
spec:
clusterIP: 10.96.98.148
externalTrafficPolicy: Cluster
ports:
- nodePort: 31000
port: 80
protocol: TCP
targetPort: 9090
selector:
app: apiserver
type: NodePort
然后用本地的 console 服务对接 k8s cluster 上的 apiserver,发现登录没问题。说明 apiserver
服务本身确实没问题,console 和 apiserver 的对接也没问题。
3.8 抓包和分析
这里要厘清整个网络拓扑,但往往很难第一时间厘清。
[pod-console: 172.25.127.32] - [vm-4: 10.1.0.11] - ? - [vm5: 10.1.0.12] - [svc-apiserver: 10.96.98.148] - [pod-apiserver: 172.25.235.30],apiserver
pod 被重启过,地址可能会变化,与之前抓包的记录不符。
此时,我们可以从两个 pod 上的包抓起。在 pod 上抓包可以用 tcpdump,但 pod 中未必安装了 tcpdump 工具。即便安装了,从 pod 中把网络包导出也不容易。因此我们推荐先找到 pod 的虚拟网卡,然后在主机节点上直接对虚拟网卡抓包。参考:https://gitee.com/dev-99cloud/training-kubernetes/blob/master/doc/class-01-Kubernetes-Administration.md#81-%E7%9B%91%E6%8E%A7%E6%97%A5%E5%BF%97%E6%8E%92%E9%94%99。如果是对 docker 容器抓包,可以参考:https://gitee.com/dev-99cloud/training-kubernetes/blob/master/doc/class-01-Kubernetes-Administration.md#17-docker-%E7%9A%84%E7%BD%91%E7%BB%9C%E6%A8%A1%E5%9E%8B
3.8.1 先对异常情况,在两端 pod 上抓包分析
在 console 和 apiserver 上抓了两组异常情况下的网络包(多抓几组,避免孤例不证),发现两组包现象类似,都可以看到 TCP ReTransmit
# 进入 pod apiserver 的 netns 抓包,172.25.127.32 是 console pod IP,9090 是 apiserver 的 pod port
tcpdump -i eth0 host 172.25.127.32 and port 9090 -w /tmp/out.cap
# 进入 pod console 的 netns 抓包,10.96.98.148 是 apiserver 的 service IP,80 是 apiserver service 的 port
tcpdump -i eth0 host 10.96.98.148 and port 80 -w /tmp/out.cap
先看 console 的网络包,最后一个请求是 /kapis/version:
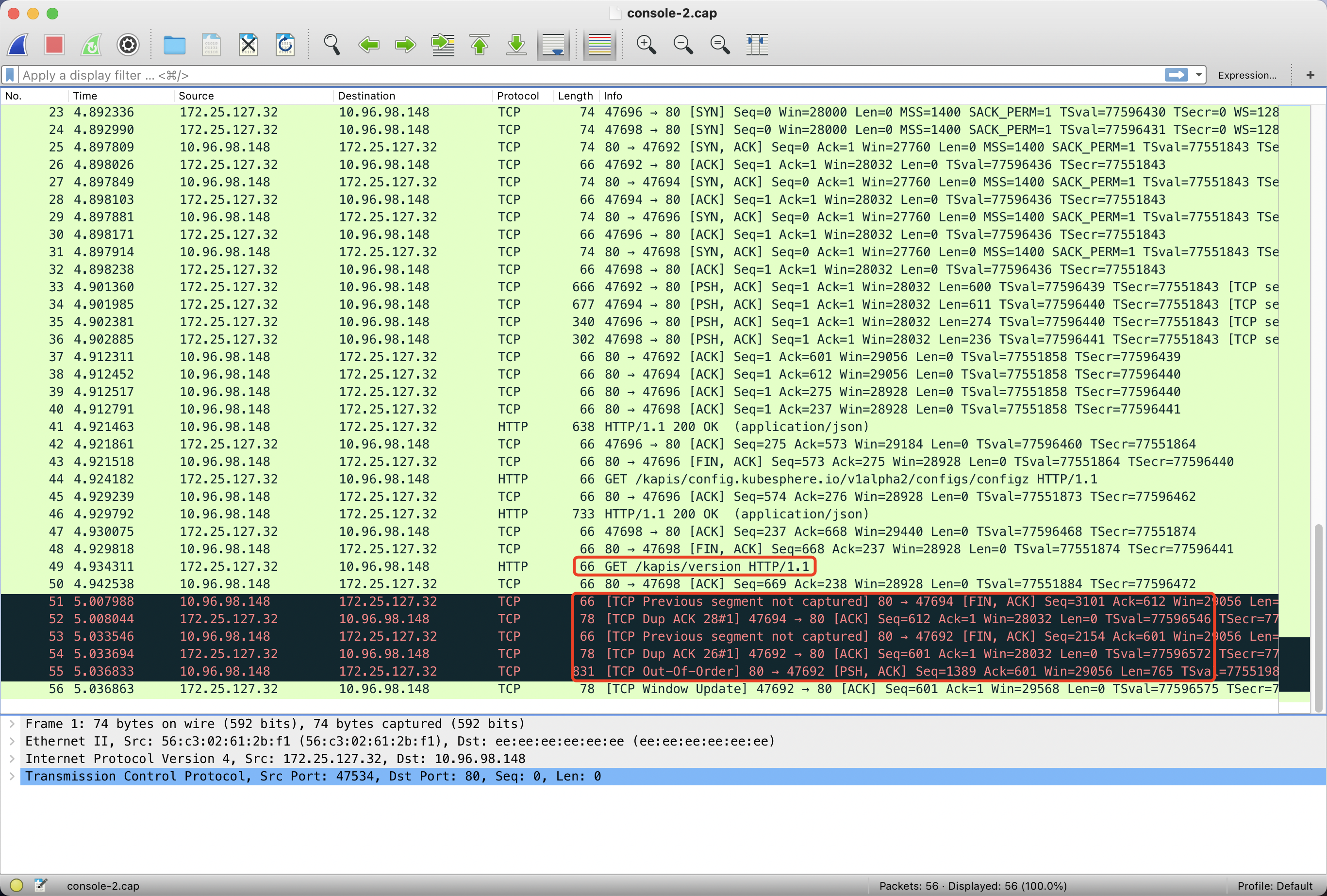
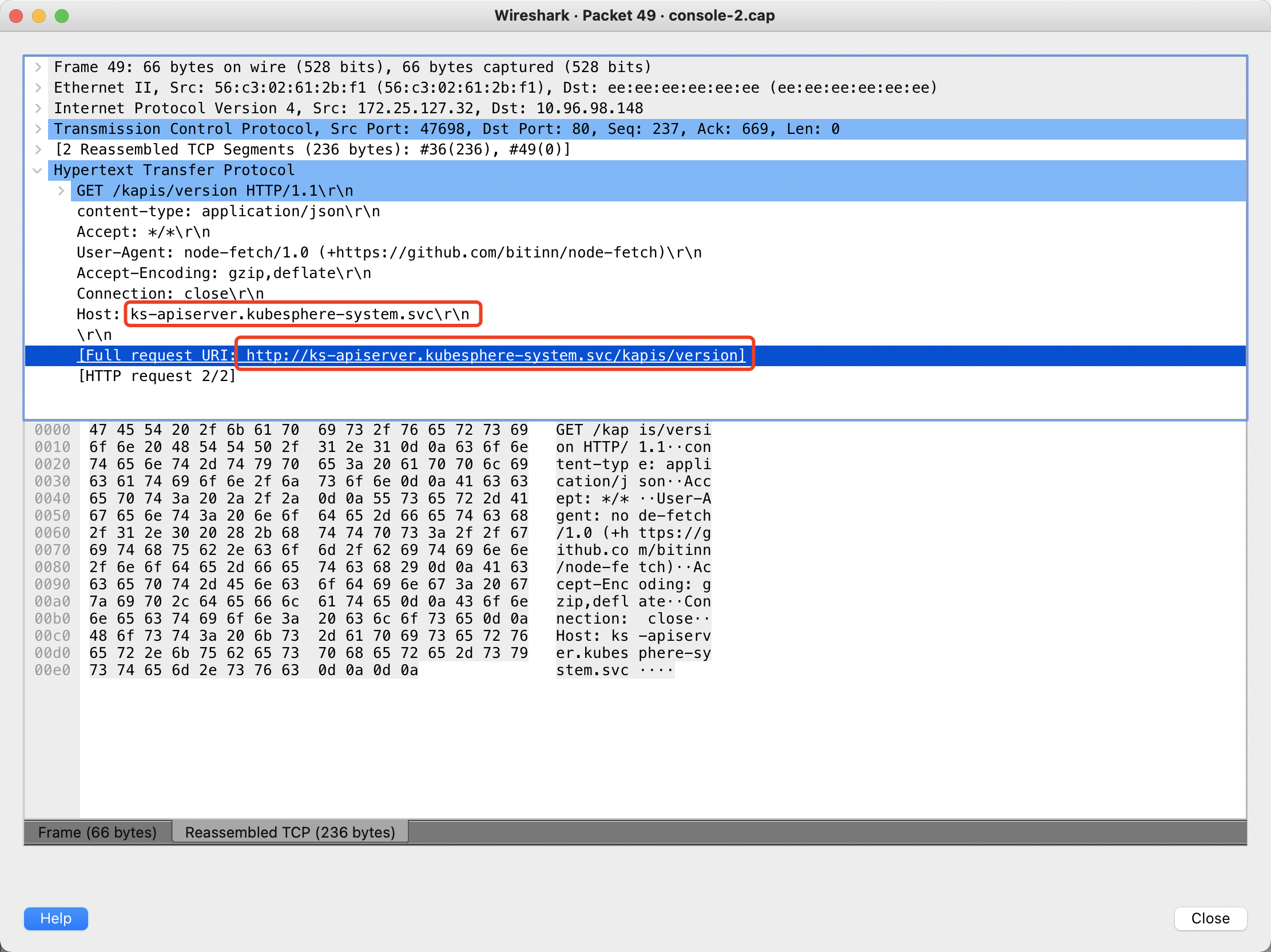
粗看之下,好像是这个 /kapis/version 这个请求没有返回,并且 Host 是 apiserver.app-system.svc,后面好像少了 .cluster.local,但继续根据这一条过滤 TCP 会话,会发现这里是 wireshark 解包不准确,实际上的 http request 是发生在三次握手之后的 PSH 包里。
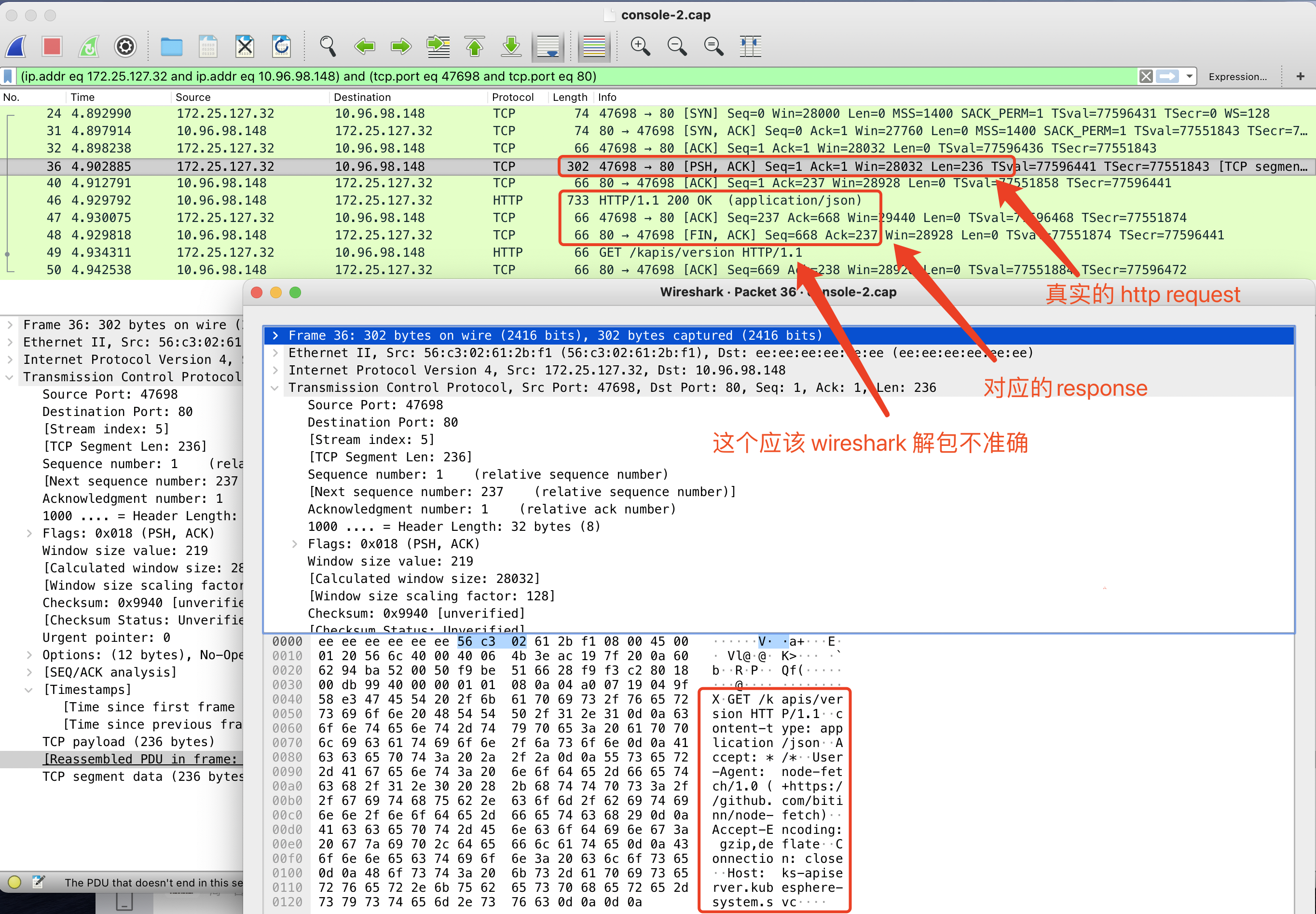
对应的 response 也正常返回了,所以这个请求没问题。后续对比正常的包,会发现正常包也这样,印证了我们的猜想。
继续对黑色背景的请求顾虑 TCP 会话,可以看到 console 上有两个 HTTP 请求没有返回。
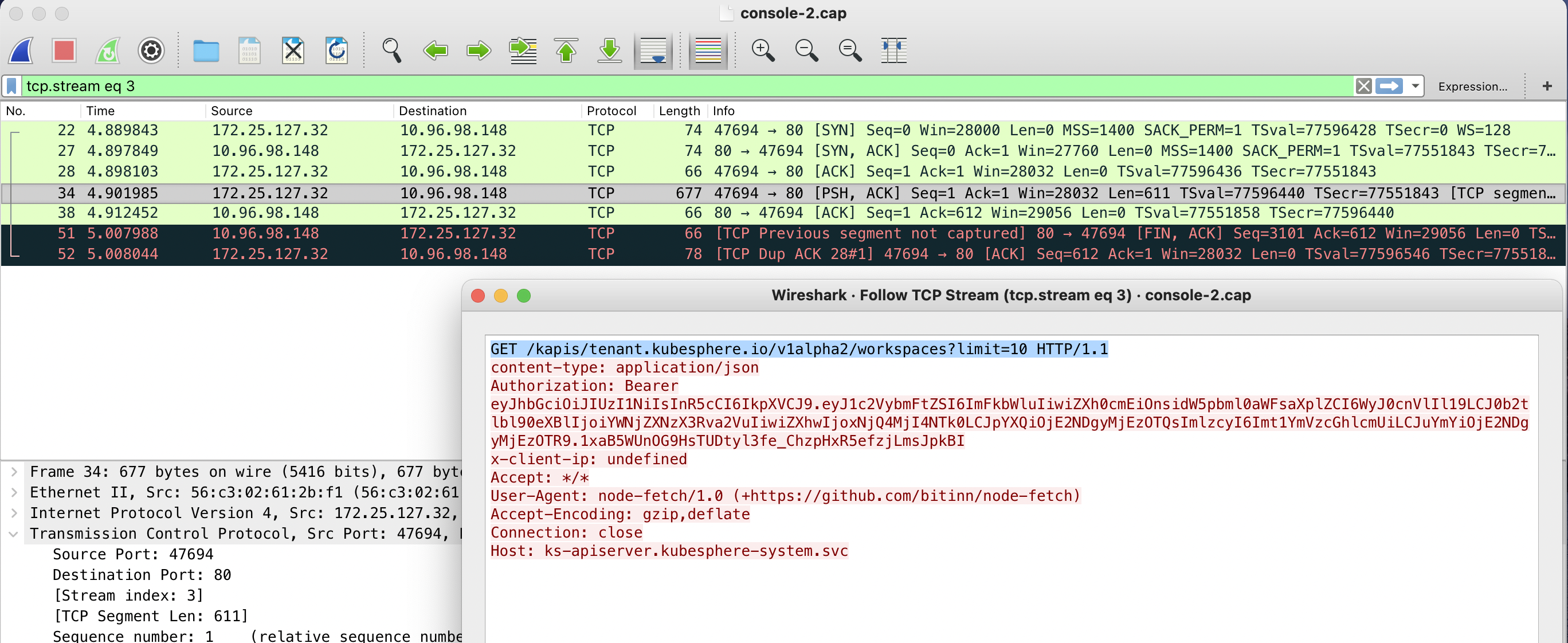
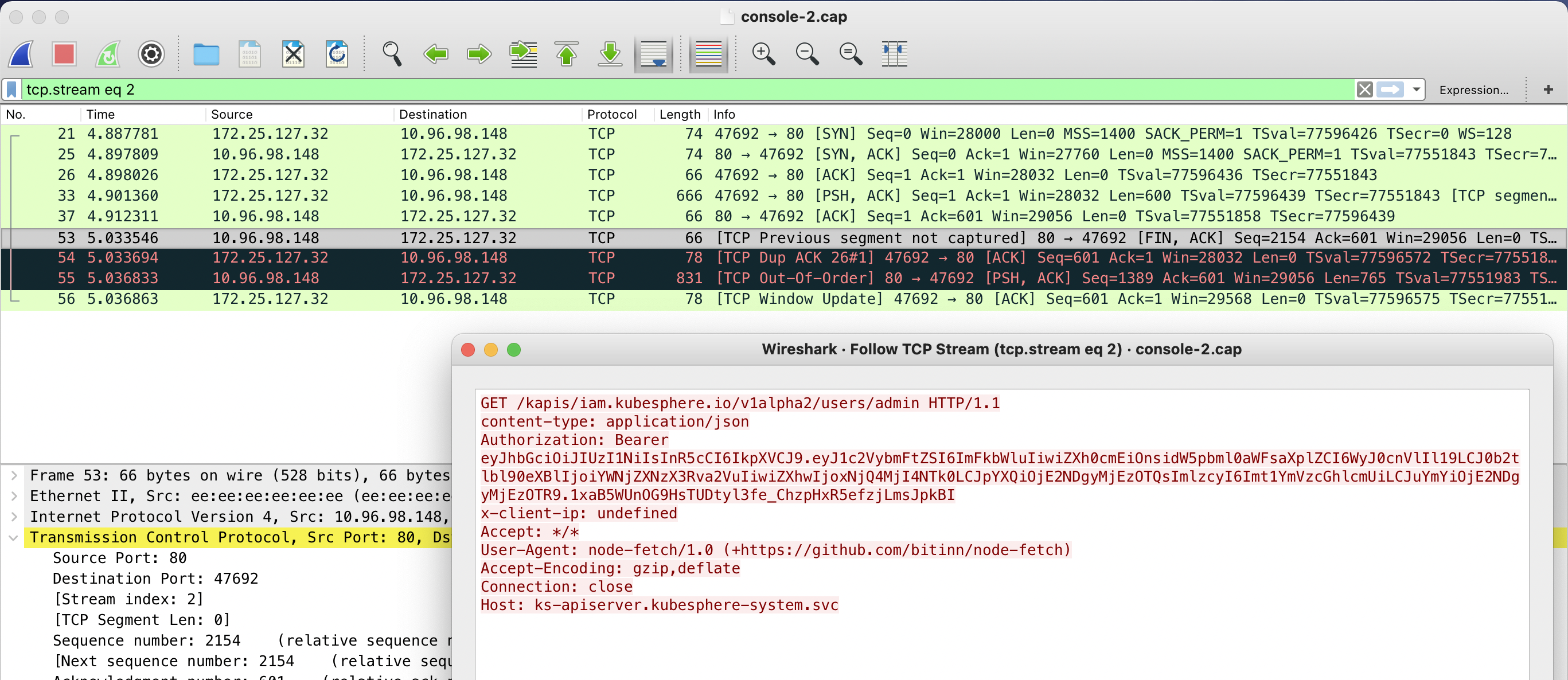
再继续看同时抓的 apiserver pod 虚拟网卡的包,可以看到 apiserver 是有正常返回的,因此不是应用层的问题,而是底层网络丢包了。
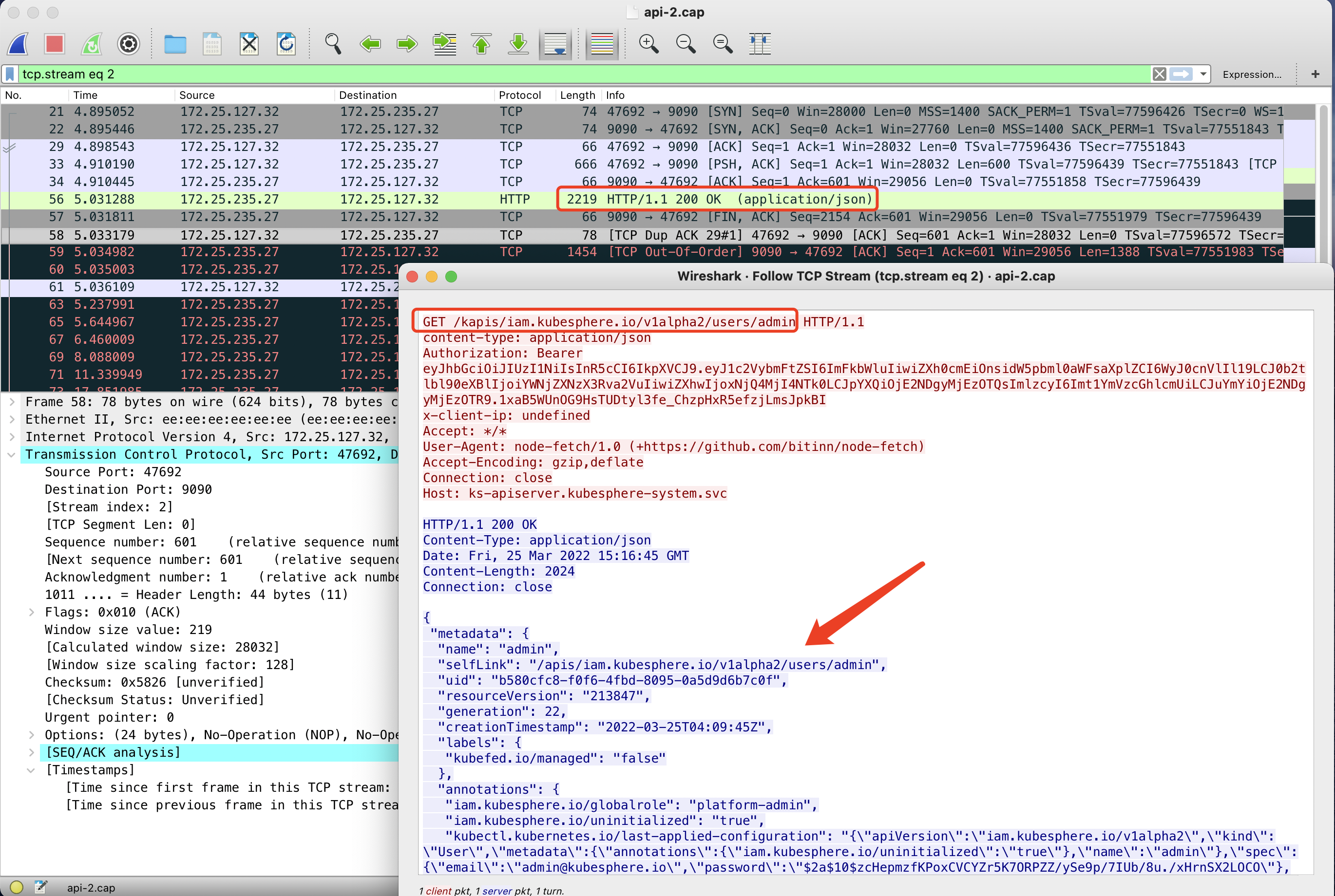
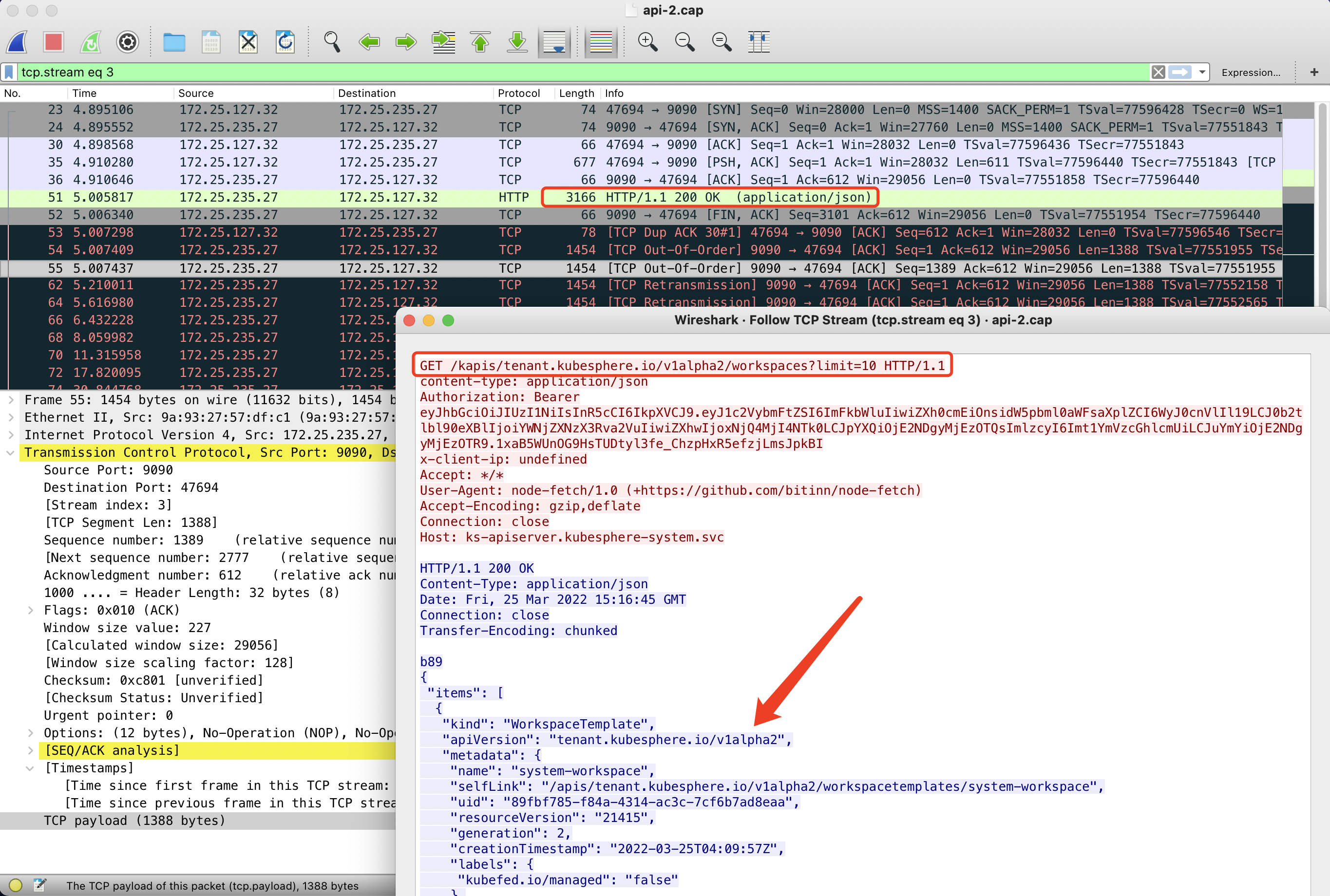
再对正常情况抓包,OK,发现 console 就收到了 apiserver 这两个 http response。
对应到应用业务代码,如果这两个包收不到,是登录不了的。
至此,线索对上了,我们能明确知道问题的直接原因,网络丢包了。
这里两个丢的 http response 都比较 size 比较大,这是个特征,记录下来。
8.3.2 接下里继续抓包,看哪两跳之间丢包
此时需要关注底层网络模型了,这个 K8S 集群的 CNI 是 Calico,用了 IPIP 模式。那拓扑就是:
[apiserver veth] - veth - tunl0 - [vm-5 eth0] - [vm-4 eth0] - tunl0 - veth - [console veth]
再对异常情况,抓 vm-5 eth0 上的包,发现 vm-5 物理网卡上没有这个回包,但是 K8S CNI tunl0 设备上有这个包。
# 对 vm-5 物理网卡抓包
tcpdump -i eth0 host 10.1.0.11 -w /tmp/vm-5.cap
# 对 veth pair 虚拟网卡抓包
tcpdump -i cali527d16a3cfa host 172.25.127.32 and port 9090 -vvv
tcpdump -i cali527d16a3cfa host 172.25.127.32 and port 9090 -w /tmp/vm-5-cali527d16a3cfa.cap
# 对 CNI tunl0 设备抓包
tcpdump -i tunl0 host 172.25.127.32 and port 9090 -vvv
tcpdump -i tunl0 host 172.25.127.32 and port 9090 -w /tmp/vm-5-tunl0.cap
注意,这里 veth pair 对问题排查没起上作用,但怎么找对应的 veth 还是比较有小技巧的,参考:https://gitee.com/dev-99cloud/training-kubernetes/blob/master/doc/class-01-Kubernetes-Administration.md#17-docker-%E7%9A%84%E7%BD%91%E7%BB%9C%E6%A8%A1%E5%9E%8B
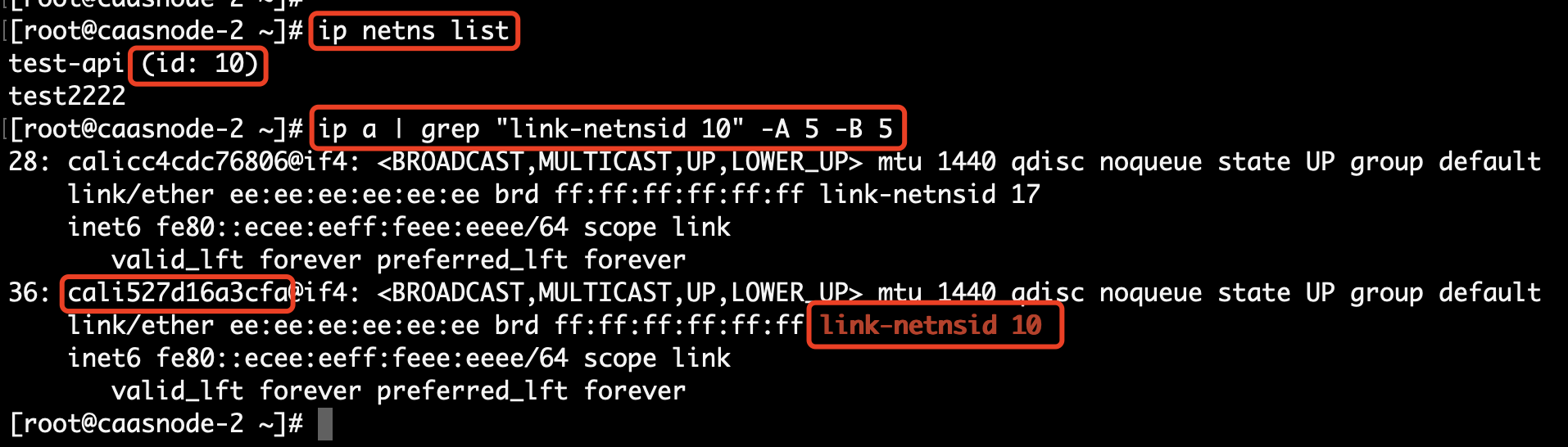
至此可以确认,http response 回包,是在 K8S CNI tunl0 设备和该 node 节点物理网卡之间丢的。tunl0 设备上有,物理网卡上没有看到。
8.3.3 追溯丢包原因
注意:如果丢包发生在两个 VM 的物理 eth0 之间,那么丢包就和 OpenStack 网络有关,我们还需要继续追溯这两个 VM 在哪两个物理节点上。
但现在丢包发生在 VM 内部,那么我们能肯定,此问题与 OpenStack 网络没有直接关系。再考虑到这两个丢包的特征是 size 比较大,小包过,大包丢,稳定重现,猜测大概率是 MTU 问题。
检查 MTU,发现果然有问题。
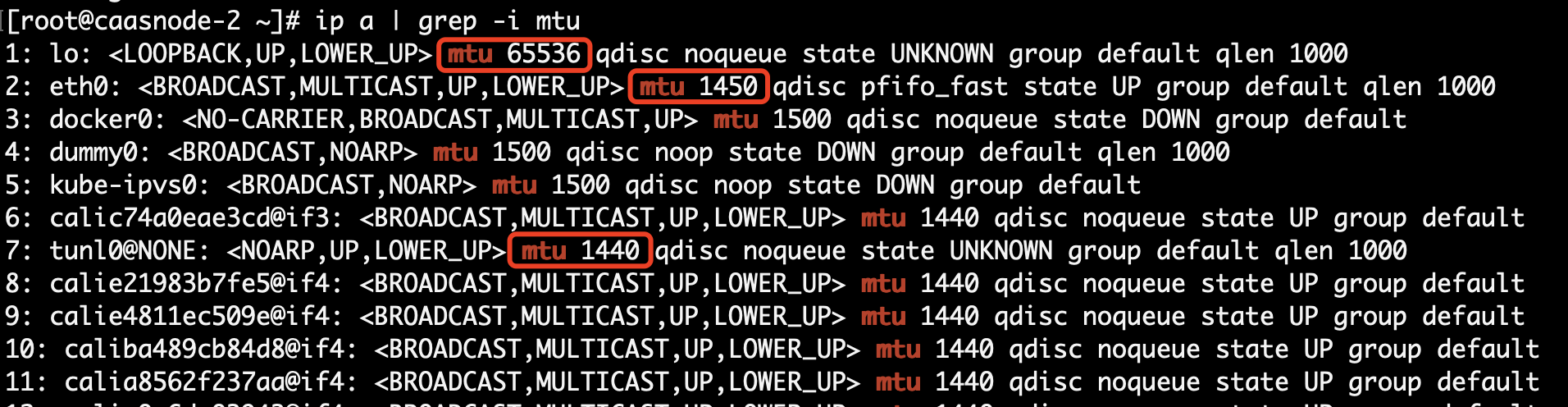
IPIP 协议是对 IP 协议再封装一层 IP,IP 头最小是 20 Bytes,那么 tunl0 mtu 如果是 1440,那么 eth0 就至少需要 1460 才满足最小 IP 头的情况,否则就会丢包。而现在,eth0 的 mtu 才 1450。
检查其它环境,VM mtu 默认都是 1500,这就是为什么之前在其它环境上测试时,IPIP 模式没有出现问题的原因(只有外层 IP 头大于 50 Bytes 才会出问题,一般不会出现)。
apiserver 和 console 在同一个节点上为什么没问题,因为本地回环的 MTU = 65536,足够大。
第一个 Host 集群没问题,是因为第一个集群用了 Calico VXLAN 模式,VXLAN 设备默认 MTU = 1400,比较小。
vxlan.calico: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue state UNKNOWN group default
4. 排查结论
- 底层 OpenStack VM eth0 MTU 设置是 1450,而 Calico IPIP tunl0 设备默认 MTU 是 1440。当应用的 IP 包大于 1430 时,IPIP 模式在跨节点时,整包大小就大于 VM eth0 MTU 1450,产生丢包。
- 应用层部分丢包导致应用部分可用,在
apiserver和console都三副本情况下,跨节点和不跨节点调用随机出现,产生各种异常现象,偶尔又正常。
5. 反思和处理建议
- OpenStack 环境上 VM 的 MTU 应该设置为 1500,其它过程设备 mtu 对应增大。
- K8S 生命周期管理需要考虑在部署之前检查节点的 MTU,少于 1500 则报警不允许安装。
- 在客户现场如果出现此类问题,无法调整 VM MTU 的情况,Calico CNI 可以尝试选择 VXLAN 模式。
