机器学习算法归类
2018-06-23
简介
预处理(Preprocessing)
- 特征提取和归一化
- 应用: 把输入数据(如文本)转换为机器学习算法可用的数据
标准化和正态化
- 标准化1:将数据转化为均值0,方差1
- 标准化2:离差标准化:
每个数据 - 数据集最小值 / (数据集最大值 - 数据集最小值) - 规范化:处理后范数为1
- 二值化:连续值 => 离散值
- 缺失处理:插值法(均值,朗格朗日)
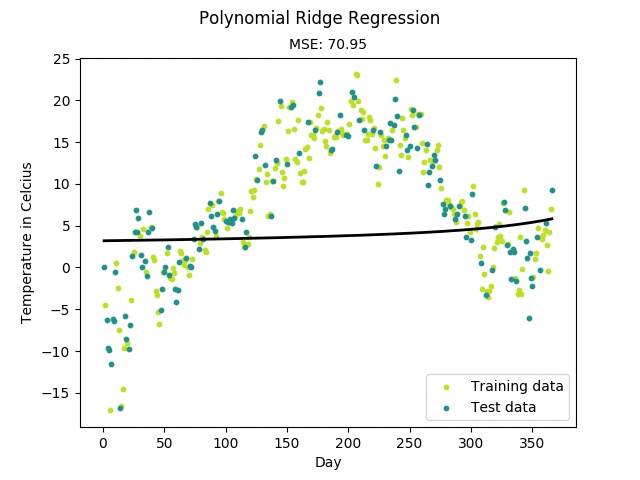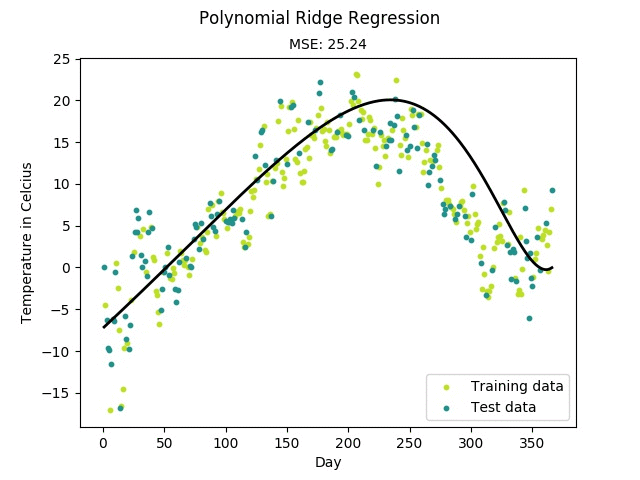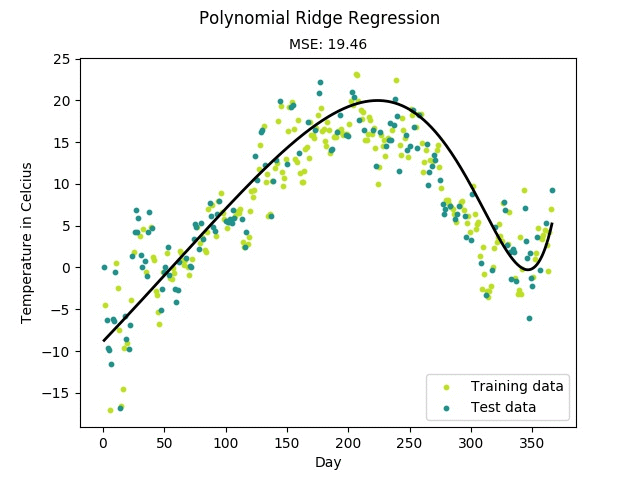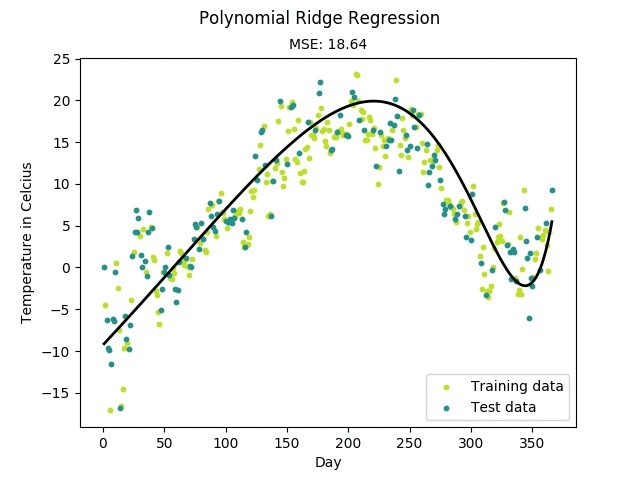
- 多项式变型:用于非线性回归预测
分类(Classification)
- 识别某个对象属于哪个类别
- 应用: 垃圾邮件检测,图像识别
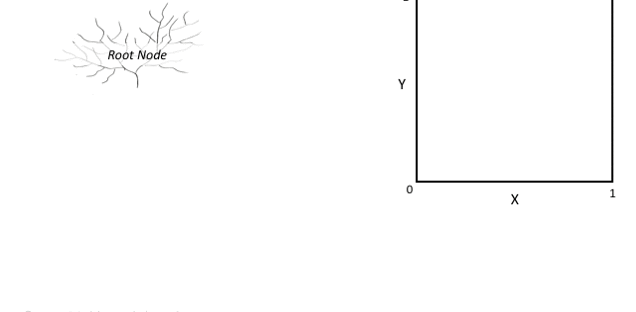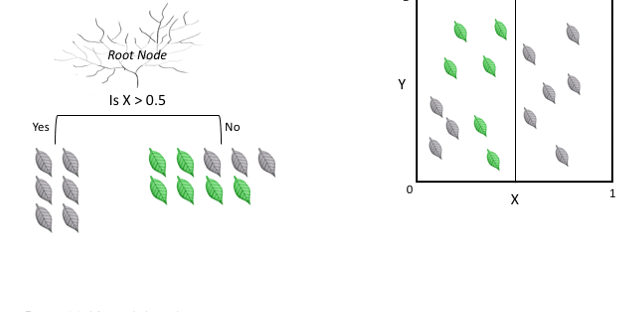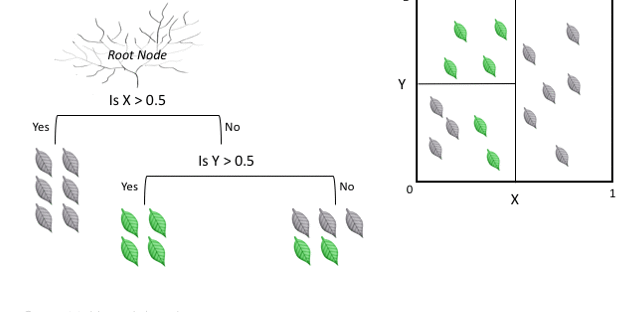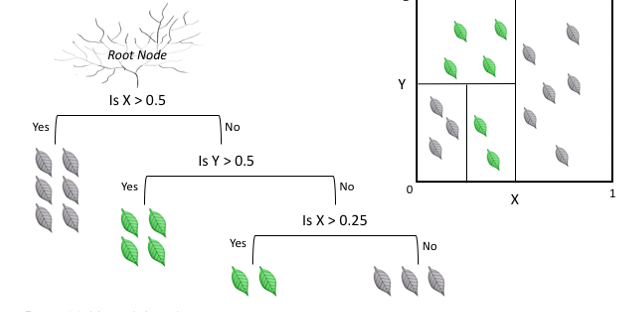
决策树(Decision Tree)
- 决策树是分类中最为基础的算法之一,其核心是依据特征的重要程度,依次使用单个特征进行分类
- 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
- 由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
支持向量机(Support vector machines,SVMs)
- 参考
-
本质上是建立核函数,令样本在高维空间上展开,然后可以一个平面分开(分类)
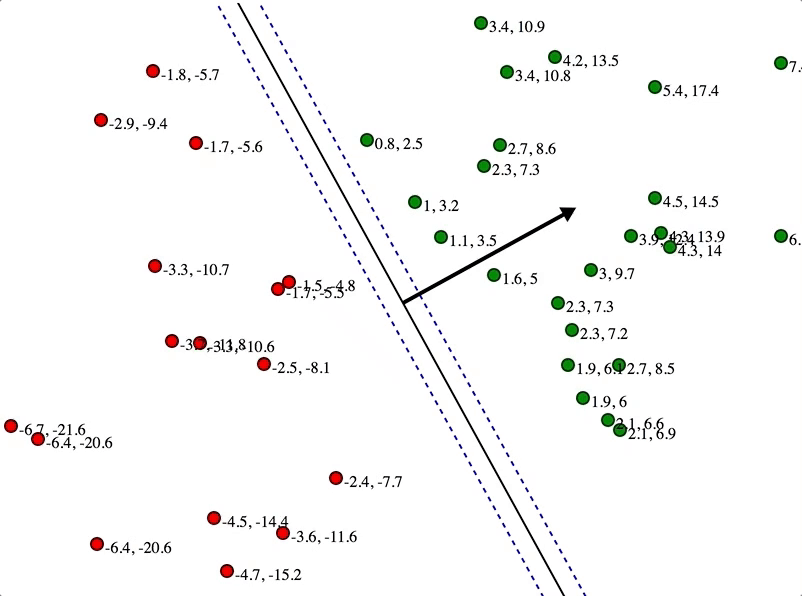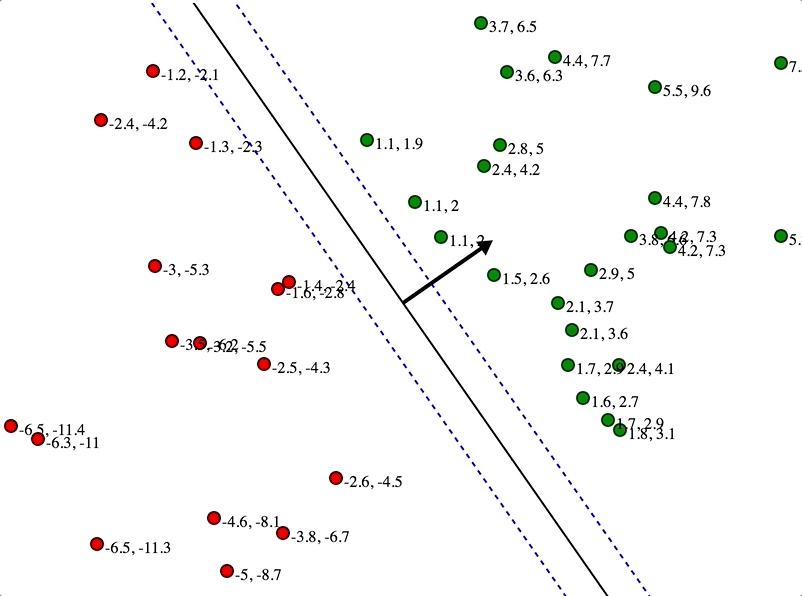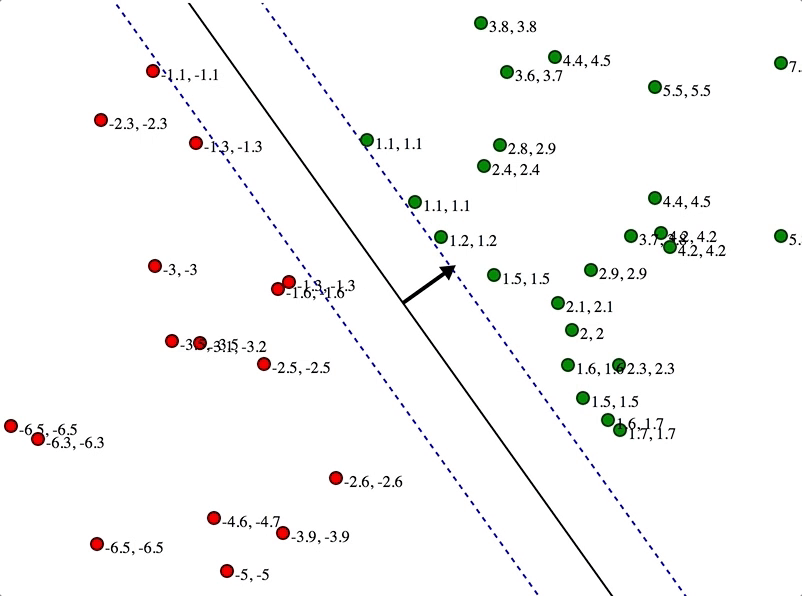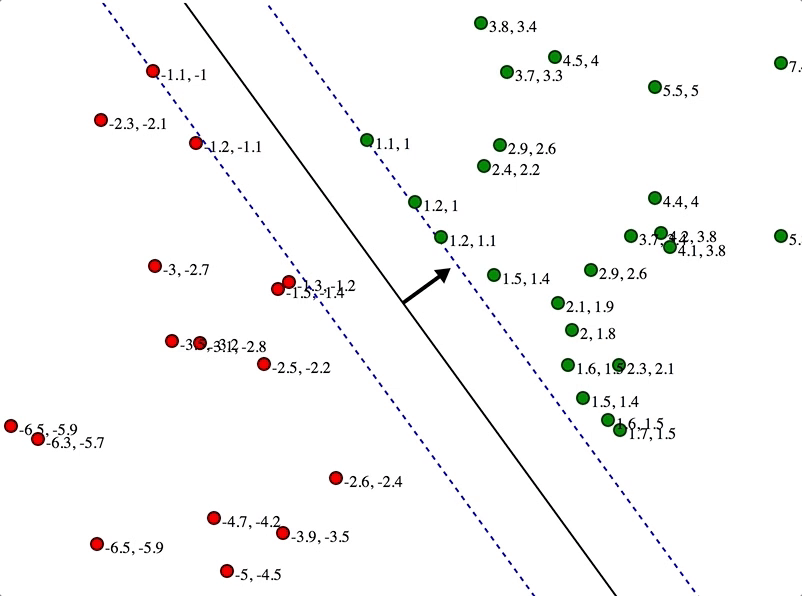
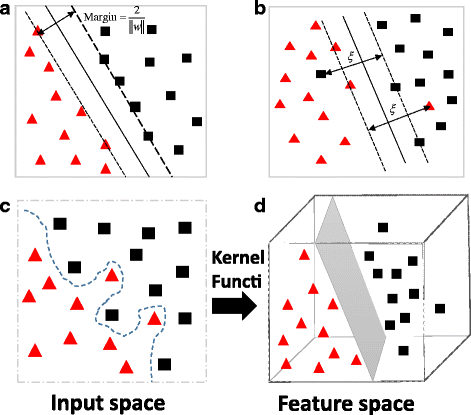
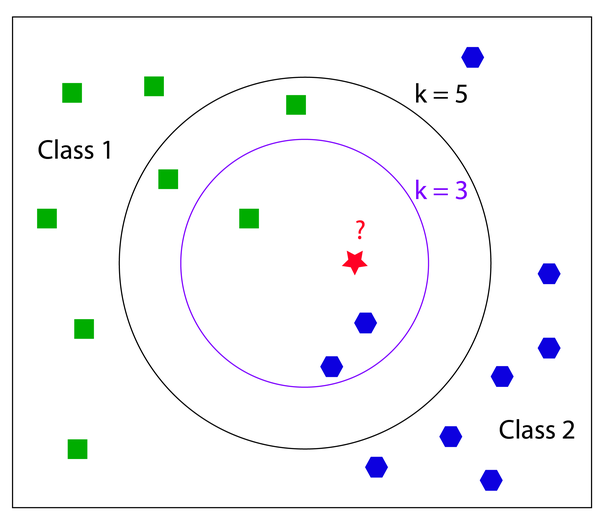
nearest neighbors
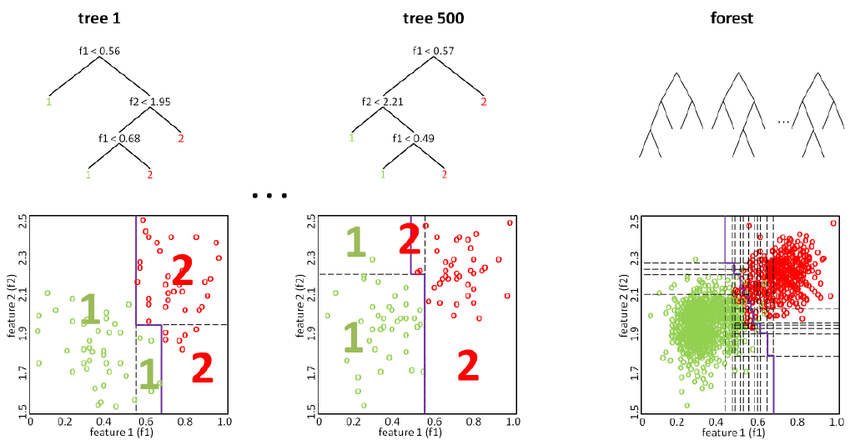
随机森林:random forest
-
评价各个特征向量的权重
回归(Regression)
- 预测与对象相关联的连续值属性
- 应用: 药物反应,股价
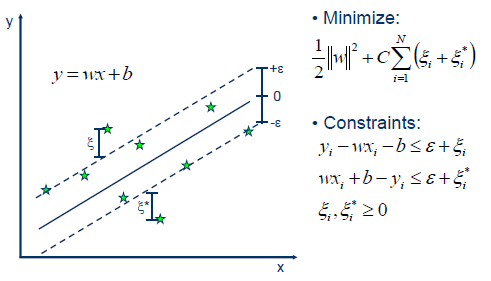
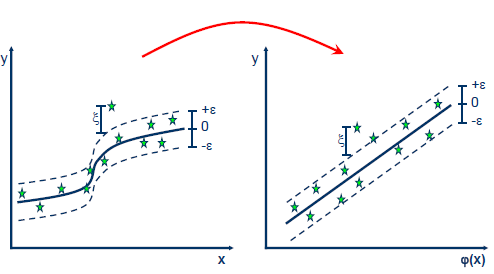
SVR
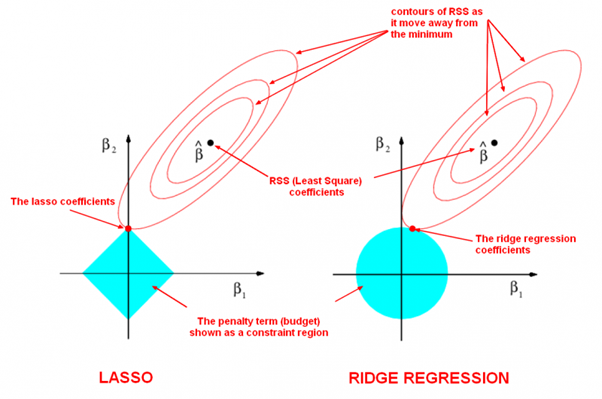
Ridge & Lasso Regression
- 当使用最小二乘法计算线性回归模型参数的时候,如果数据集合矩阵(也叫做设计矩阵(design matrix))X,存在多重共线性,那么最小二乘法对输入变量中的噪声非常的敏感,其解会极为不稳定。
- 当设计矩阵X存在多重共线性的时候(数学上称为病态矩阵),最小二乘法求得的参数w在数值上会非常的大,而一般的线性回归其模型是
y = w^T * x - 显然,就是因为w在数值上非常的大,所以,如果输入变量x有一个微小的变动,其反应在输出结果上也会变得非常大,这就是对输入变量总的噪声非常敏感的原因。
- 如果能限制参数w的增长,使w不会变得特别大,那么模型对输入w中噪声的敏感度就会降低。这就是脊回归和套索回归(Ridge Regression and Lasso Regrission)的基本思想。
- 当设计矩阵X存在多重共线性的时候(数学上称为病态矩阵),最小二乘法求得的参数w在数值上会非常的大,而一般的线性回归其模型是
- 为了限制模型参数w的数值大小,就在模型原来的目标函数上加上一个惩罚项,这个过程叫做正则化(Regularization)。
- 如果惩罚项是参数的l2范数,就是脊回归(Ridge Regression)
- 如果惩罚项是参数的l1范数,就是套索回归(Lasso Regrission)
-
正则化同时也是防止过拟合有效的手段,这在“多项式回归”中有详细的说明。
聚类(Clustering)
- 将相似对象自动分组
- 应用: 客户细分,分组实验结果
k-Means
- 原理
- K-means 通常被称为 Lloyd’s algorithm(劳埃德算法)
- 第一步是选择initial centroids(初始质心),最基本的方法是从X数据集中选择k个样本
- 初始化完成后,K-means 由两个其他步骤之间的循环组成
- 第二步将每个样本分配到其 nearest centroid (最近的质心)
- 第三步通过取分配给每个先前质心的所有样本的平均值来创建新的质心
- 计算旧的和新的质心之间的差异,并且算法重复这些最后的两个步骤,直到该值小于阈值
-
换句话说,算法重复这个步骤,直到质心不再显著移动
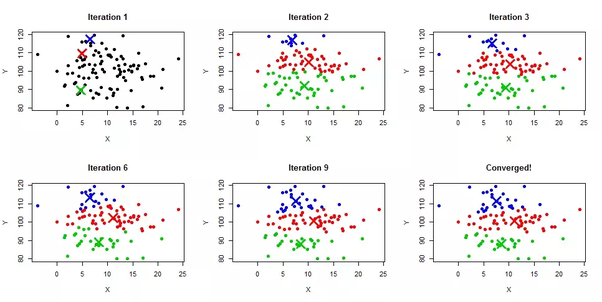
- 适用场景
- K-means算法通常可以应用于维数、数值都很小且连续的数据集
- 比如:从随机分布的事物集合中将相同事物进行分组
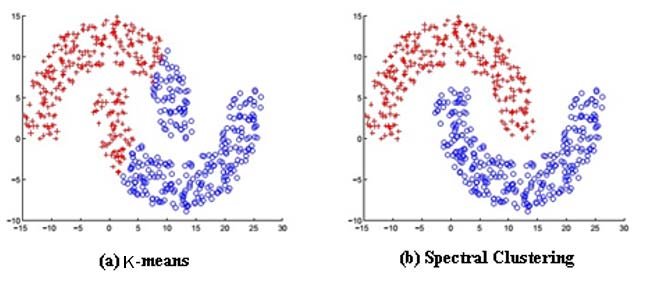
spectral clustering
- 谱聚类是从图论中演化出来的算法,后来在聚类中得到了广泛的应用。
- 它的主要思想是:
- 把所有的数据看做空间中的点,这些点之间可以用边连接起来
- 距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高
- 通过对所有数据点组成的图进行切图
- 让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高
- 从而达到聚类的目的
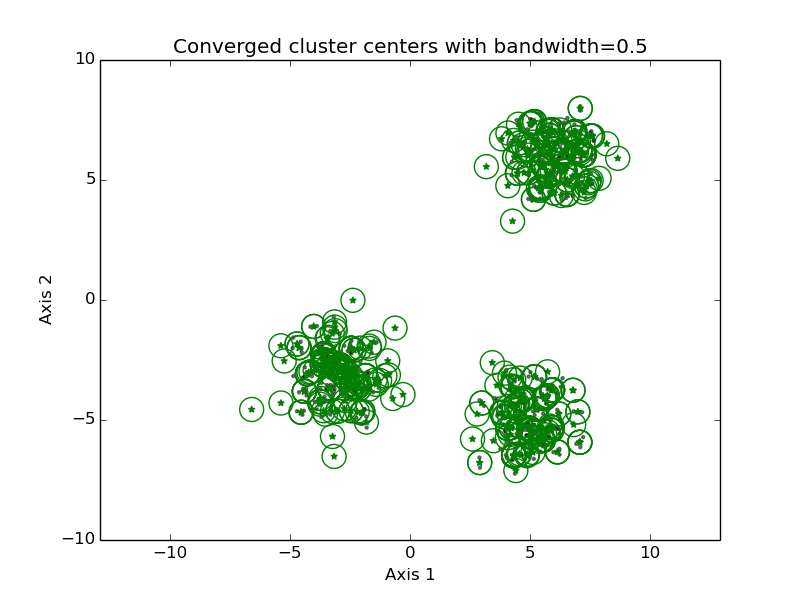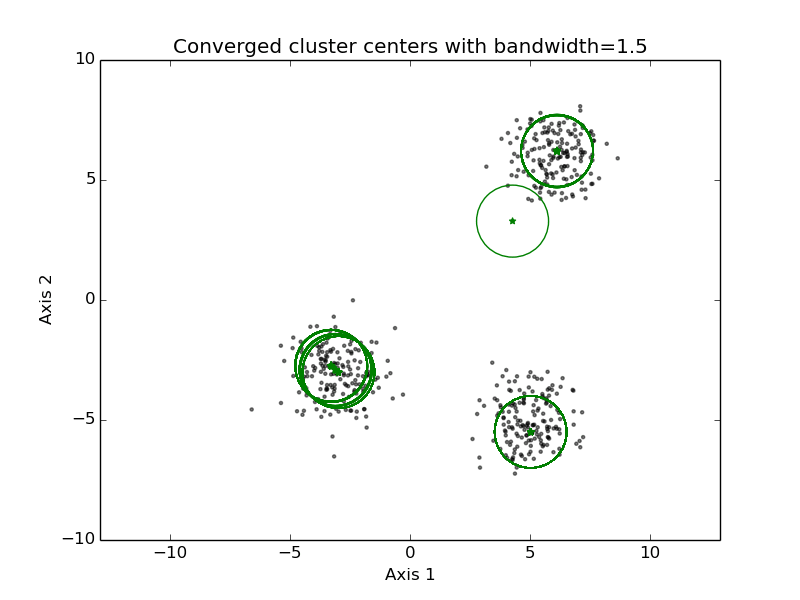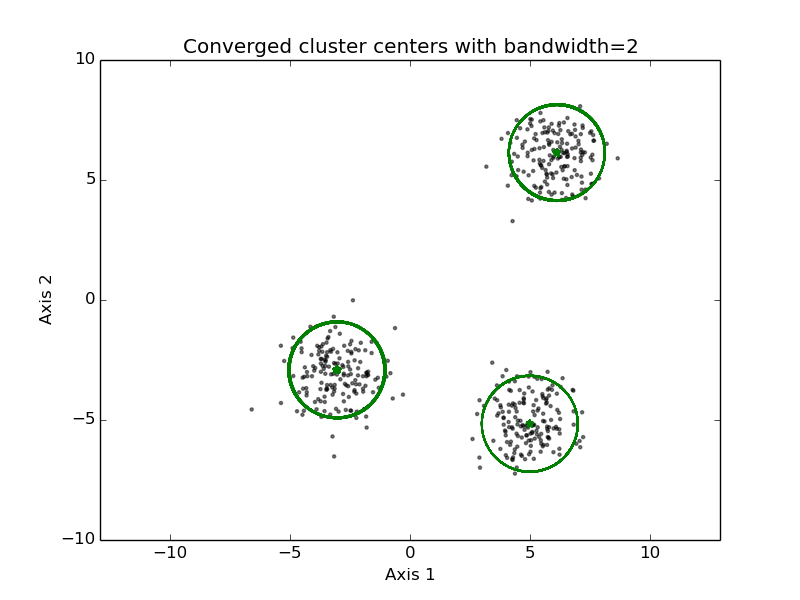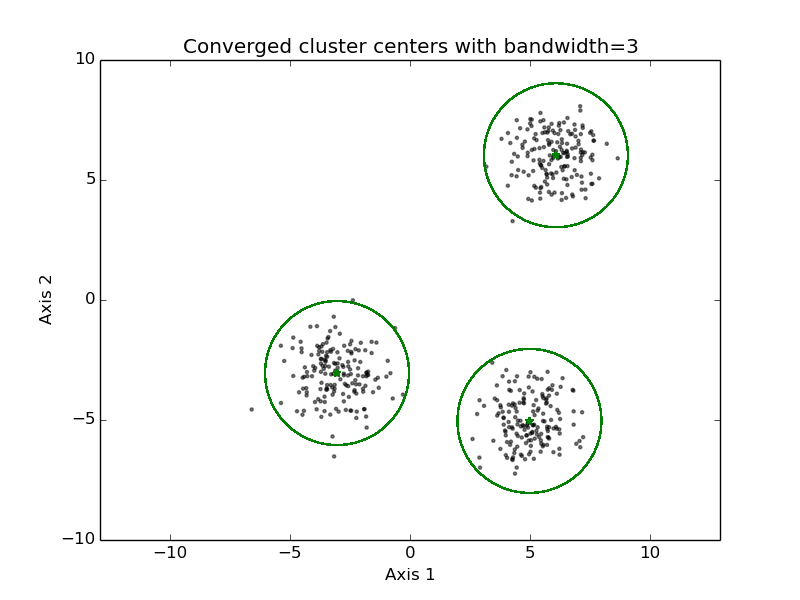
mean-shift clustering
- 步骤
- Initialize cluster prototype each of the data points in the set (or a random sub-selection of the set)
- For every cluster prototype do:
- Find the points in the data set that are within B distance of it
- New cluster prototype location is the mean of those points
- Iterate until there is no change of points within B distance
- Merge all cluster prototypes that are close by
- It is possible to use a different kernel in step 2, to give a higher weight to points closer to the cluster prototype center
降维(Dimensionality reduction)
- 减少要考虑的随机变量的数量
- 应用: 可视化,提高效率
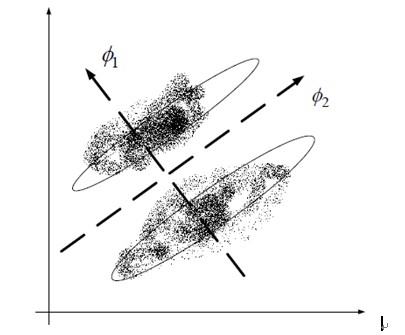
PCA(Principal Component Analysis)主成分分析算法
- PCA追求的是在降维之后能够最大化保持数据的内在信息
- 并通过衡量在投影方向上的数据方差的大小来衡量该方向的重要性
- 但是这样投影以后对数据的区分作用并不大,反而可能使得数据点揉杂在一起无法区分
- 这也是PCA存在的最大一个问题,这导致使用PCA在很多情况下的分类效果并不好
-
具体可以看下图所示,若使用PCA将数据点投影至一维空间上时,PCA会选择2轴,这使得原本很容易区分的两簇点被揉杂在一起变得无法区分;而这时若选择1轴将会得到很好的区分结果。
LDA(Linear Discriminant Analysis)
- 也有叫做Fisher Linear Discriminant)是一种有监督的(supervised)线性降维算法。与PCA保持数据信息不同,LDA是为了使得降维后的数据点尽可能地容易被区分!
- 假设原始数据表示为X,(m*n矩阵,m是维度,n是sample的数量)
- 既然是线性的,那么就是希望找到映射向量a, 使得 a‘X后的数据点能够保持以下两种性质:
- 同类的数据点尽可能的接近(within class)
- 不同类的数据点尽可能的分开(between class)
局部线性嵌入(LLE)
- Locally linear embedding 是一种非线性降维算法,它能够使降维后的数据较好地保持原有流形结构。
- LLE可以说是流形学习方法最经典的工作之一,很多后续的流形学习、降维方法都与LLE有密切联系。
-
如下图,使用LLE将三维数据(b)映射到二维(c)之后,映射后的数据仍能保持原有的数据流形(红色的点互相接近,蓝色的也互相接近),说明LLE有效地保持了数据原有的流行结构。
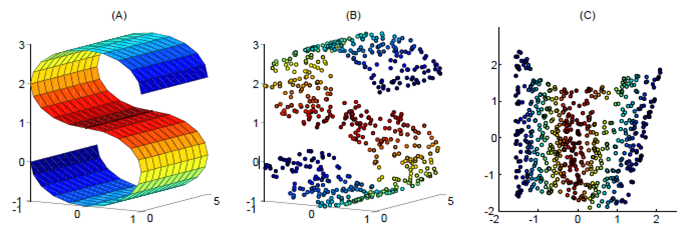
- 但是LLE在有些情况下也并不适用,如果数据分布在整个封闭的球面上,LLE则不能将它映射到二维空间,且不能保持原有的数据流形。那么我们在处理数据中,首先假设数据不是分布在闭合的球面或者椭球面上。
non-negative matrix factorization(非负矩阵分解)
- 定义:
- 输入:非负矩阵V
- 输出:两个非负矩阵W和H
- 目标:V=WH
- 利用矩阵分解来解决实际问题的分析方法很多,如
- PCA(主成分分析)
- ICA(独立成分分析)
- SVD(奇异值分解)
- VQ(矢量量化)
- 这些方法的共同特点是:
- W和H中的元素可为正或负
- 即使输入的初始矩阵元素是全正的,传统的秩削减算法也不能保证原始数据的非负性。
- 在数学上,从计算的观点看,分解结果中存在负值是正确的,但负值元素在实际问题中往往是没有意义的。
- 例如图像数据中不可能有负值的像素点;在文档统计中,负值也是无法解释的。
-
通俗点说,VQ是用一张完整的图像直接代表源脸部图像;PCA是将几个完整人脸加减压成一张脸;而NMF是取甲的眼睛,乙的鼻子,丙的嘴巴直接拼成一张脸。

模型选择(Model selection)
- 比较,验证,选择参数和模型
- 目标: 通过参数调整提高精度
grid search
- 网格搜索实际上就是暴力搜索:
- 首先为想要调参的参数设定一组候选值
- 然后网格搜索会穷举各种参数组合
- 根据设定的评分机制找到最好的那一组设置
cross validation
- 交叉验证,有时亦称循环估计,是一种统计学上将数据样本切割成较小子集的实用方法。
- 于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证。
- 一开始的子集被称为训练集。而其它的子集则被称为验证集或测试集。
- 交叉验证的目标是在训练阶段定义一组用于“测试”模型的数据集,以便减少像过拟合的问题,得到该模型将如何衍生到一个独立的数据集的提示。
- 交叉验证的理论是由Seymour Geisser所开始的。
- 它对于防范根据数据建议的测试假设是非常重要的,特别是当后续的样本是危险、成本过高或科学上不适合时去搜集。
